小红书是一个生活方式平台和消费决策入口,是当前著名的电商平台。和其他电商平台不同,小红书是从社区起家。在小红书社区,用户通过文字、图片、视频笔记的分享,记录了这个时代年轻人的正能量和美好生活。
2014年10月小红书福利社上线,旨在解决海外购物的另一个难题:买不到。小红书通过机器学习对海量信息和人进行精准、高效匹配,已累积海量的海外购物数据,分析出最受欢迎的商品及全球购物趋势,并在此基础上把全世界的好东西,以最短的路径、最简洁的方式提供给用户。
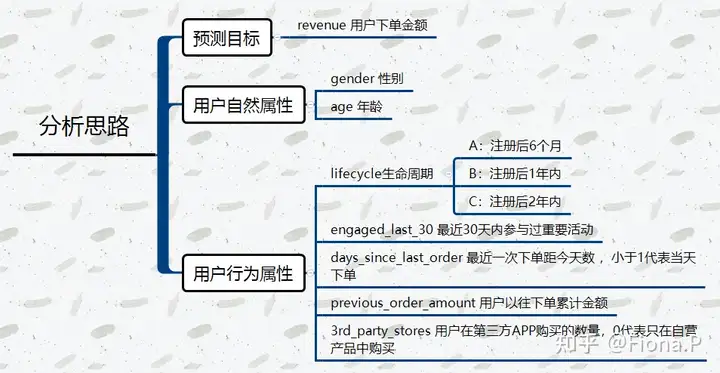
本文将根据小红书的数据,利用python线性回归,对小红书的销售额进行预测。
数据字典:
revenue:用户的下单购买金额(预测目标)
3rd_party_stores:用户过往在APP中从第三方商家购买的数量,0代表只在自营产品中购买
gender:性别,1为男性,0为女性,未知则空缺
age:年龄,未知为空缺
engaged_last_30:最近30天在APP上有参与重点活动(讨论,买家秀等)
lifecycle 生命周期分类为A,B,C(分别对应注册后6个月内,1年内,2年内)
days_since_last_order 最近一次下单距今的天数(小于1则代表当天有下单)
previous_order_amount: 以往累积的用户购买金额数据维度划分:
数据分析流程:
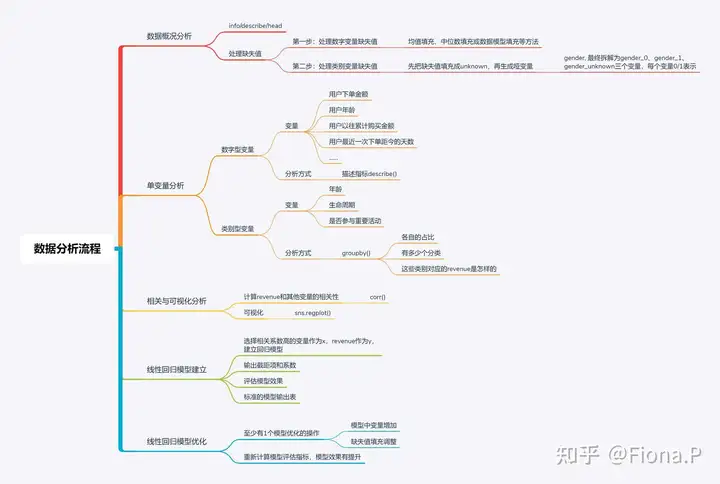
3.1数据概况分析
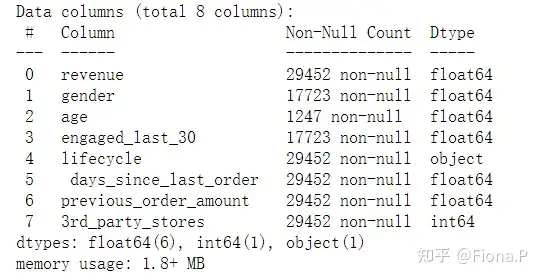

1、有3个变量存在缺失值,缺失比例: 性别:40%、年龄:96%、最近30天参与重大活动:40%;需要对3个变量进行数据填充,其中:年龄缺失比例大,参考价值小;
2、lifecycle是分类型变量,需要转换成数值型变量;
查看转换后的数据
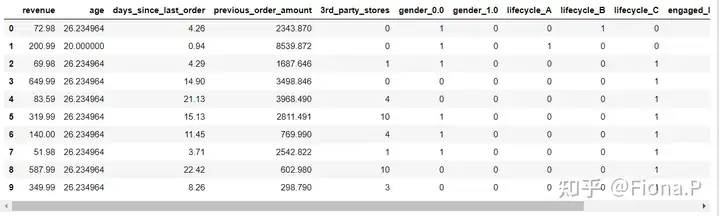
3.2 单变量分析
由于某些变量变为哑变量,不方便可视化,这里用原数据red进行分析
1.目标变量分析
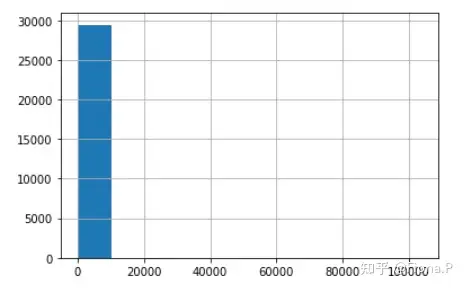
revenue数据范围在10000以内,现缩小数据范围
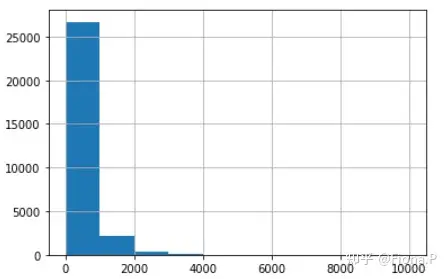
revenue数据范围在2000以内,缩小数据范围到2000以内
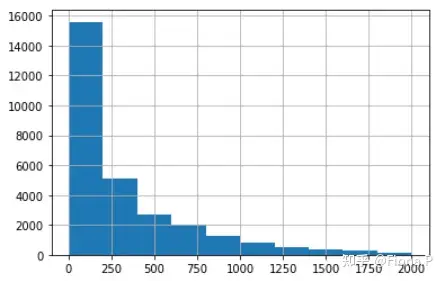
现在可以看到数据集中在250以内,但考虑到样本量,不再缩减范围。查看一下revenue在2000以内的样本量
查看销售额在2000以内的样本数量为28866,与原数据29452相差不大,因此可以接受“revenue<2000”这个更加有效的分析范围。但2000这个值是我们自己猜测和指定的,为了使分析结果更加准确,我们需要计算出销售额的离群值。
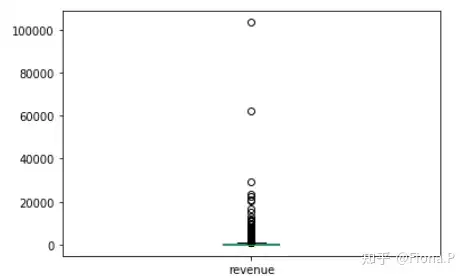
一般我们默认,超过75%分位数的1.5倍四分位数的数值为离群值
剔除离群值之后,样本容量为27286,可以接受。
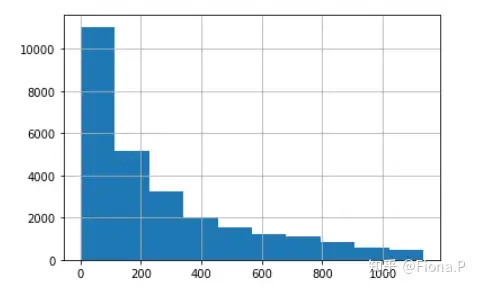
2.其他变量分析
数字型变量分布
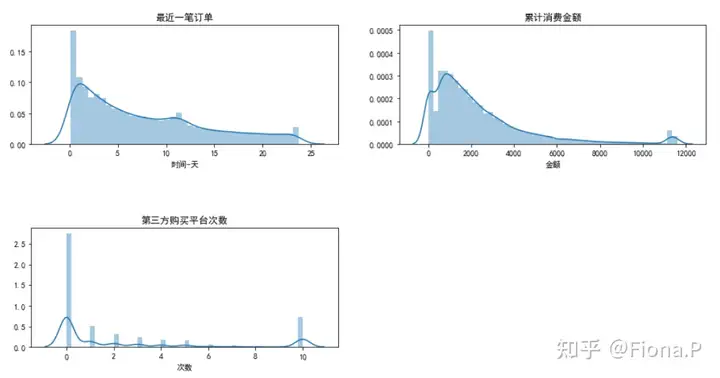
我们发现小红书会员中,大部分用户最近半个月以来都有使用小红书购买商品,大部分用户购买商品的累计金额在5000以内,说明小红书的活跃用户以小额的商品购买为主;同时我们看到,仅有少量的用户会选择第三方商家,说明用户购买商品时倾向于选择自营。
分类型变量分布
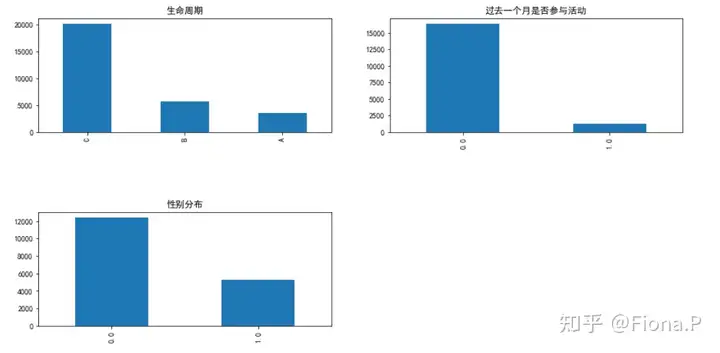
小红书的用户中女性群体要多于男性群体,甚至是男性的两倍。大部分用户并没有参与重点活动。可以通过用户调研深入探究问题和原因,以便调整营销策略。·A,B,C分别代表用户注册6个月,1年和2年。从上图我们发现,超过一半的用户是注册2年及以上的。
3.3多变量分析
为了能更准确地把握各变量与目标变量之间的关系,为建立回归模型奠定基础,我们使用red1基础上剔除离群值后的新表red2。
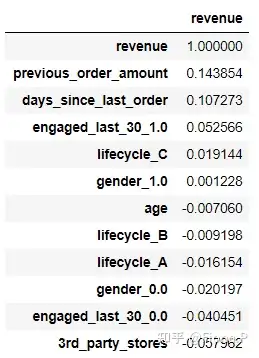
通过计算相关系数我们发现,各个变量对目标变量(销售额)的相关性都比较弱,但为了查看是否有其他非线性关系的存在,我们仍需要作出散点图。
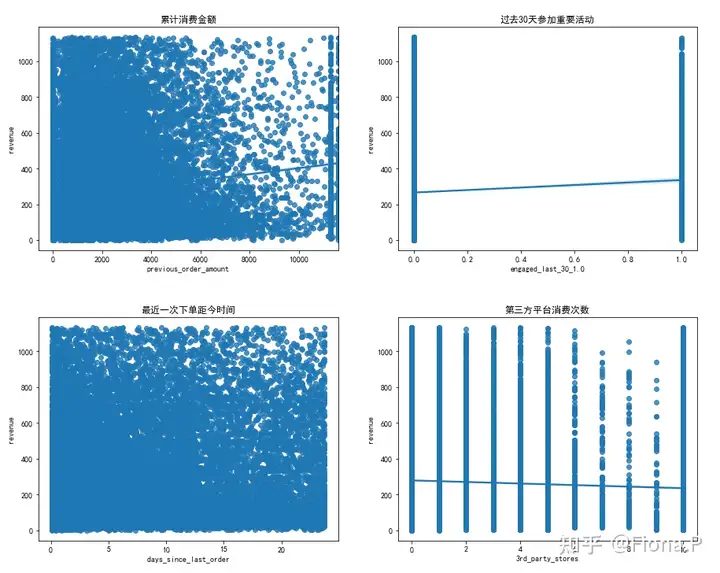
数字变量与目标变量revenue的关系
分类变量与目标变量revenue的关系
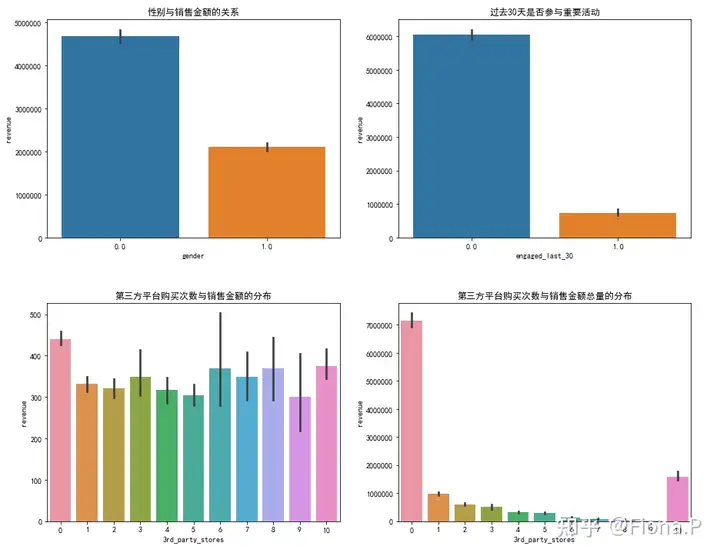
可以看出,参与活动的用户平均销售额要高于未参与活动的用户,因此通过用户调研改进营销活动继而提高营业额是很有必要的。
用户是否在第三方商家购买商品或者购买的数量多少,与平均销售额的因果关系不是很大;但从总销售额的角度来看,从第三方购买商品的用户对小红书营业额的贡献较低,两者可能存在负相关关系。
3.4 回归分析
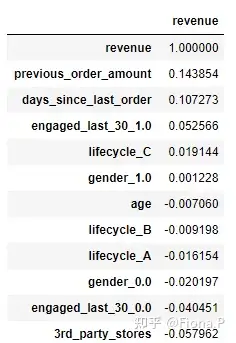
模型评估
如表,模型的R值为0.021,即该模型仅能对营业额变动的2.1%作出解释,解释能力太弱,我们需要进一步优化模型
经过多次优化,选择最佳变量入参,R值从0.021提升到0.043
·回归方程为:
y=0.016(previous_order_amount)+6.10(days_since_last_order)-6.33(3rd_party_stores)+31.48(engaged_last_30_1.0)-19.29(engaged_last_30_0.0)+209.94
·解读为:
用户在小红书的累计花费每增加1000个单位,销售额就增加16个单位;
最近一次下单的天数每增加1天,销售额就增加6.1个单位;
用户每从第三方购买1个商品,销售额就减少6.3个单位;
每增加一位参与重点活动的用户,销售额就增加31.48个单位,每减少一位参与重点活动的用户,销售额就减少19.29个单位;
第一次在小红书上购买商品的用户可贡献209.94个单位的营业额。4.业务建议
1)通过用户调研,深入探究用户参与重点活动的相关特征,改进营销方案,促进用户参与营销活动,以提升销售额;
2)发放限时优惠券,鼓励用户凑单,增加累计消费;
3)对第三方平台销售产品进行调研,做竞品分析,开发有竞争力的产品。

 关注微信
关注微信